
TEN Agent 调研
TEN Agent 特性
- 支持多模态交互,包括视频和语音的输入,文本和语音的输出
- 支持实时对话
体验地址:TEN Agent
应用架构
后端根据 JSON 配置拉起 Worker 进程,并通过声网接口和前端实时交互。在每个 Worker 中,会通过 TEN 框架来运行 Agent 逻辑。
flowchart LR
subgraph Frontend["前端"]
Config["配置逻辑"]
Conn["开启和关闭连接逻辑"]
Interaction["Agent 交互逻辑"]
end
subgraph Backend["后端"]
Dev["Dev Server"]
Json["JSON 配置文件"]
Web["Web Server"]
Worker1["Worker"]
Worker2["Worker"]
Worker3["Worker"]
end
Agora["Agora"]
Config -- "HTTP 接口" --> Dev
Conn -- "HTTP 接口" --> Web
Dev <-->|读写| Json
Web -- "加载" --> Json
Web -- "启动和关闭" --> Worker1
Web -- "启动和关闭" --> Worker2
Web -- "启动和关闭" --> Worker3
Interaction -- "实时交互 RTC" --> Agora
Agora -- "实时交互 RTC" --> Worker1
TEN 框架
TEN 框架可以看作一个支持实时交互的编排框架,可以将节点编排为有向循环图。
在通过 TEN 创建一个 Agent 应用时,有两个核心要素需要定义:
- Extention:Graph 节点的具体代码实现,支持 Python 和 Go 等语言。
- JSON 描述:Graph 节点和编排逻辑的声明式描述。
在给出 Extention 以及 JSON 描述后,TEN 运行时会完成 Graph 执行等逻辑。
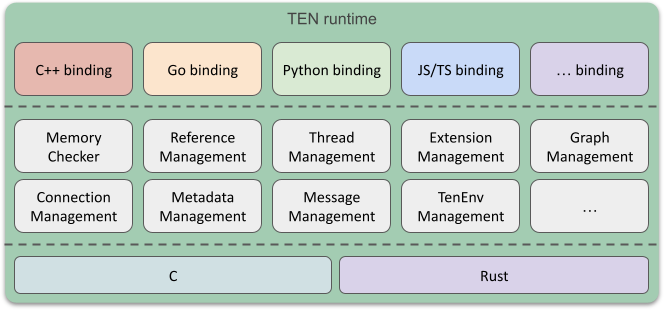
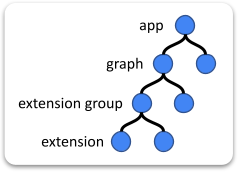
PDF 中的 TEN Framework 概念图可以在官方文档的 Overview 中找到,对应的是 TEN runtime 的分层结构和 app、graph、extension group、extension 的层级关系。
官方图:
flowchart LR
Client["TEN client"] -- "graph configuration" --> Graph["Graph"]
Prebuilt["Prebuilt graph"] -- "graph configuration" --> Graph
subgraph App["App"]
Graph
E1["Ext"]
E2["Ext"]
E3["Ext"]
E4["Ext"]
Graph --> E1
Graph --> E2
E1 --> E3
E2 --> E3
E3 --> E4
E4 --> E1
end
TEN 的概念层级:
app
└── graph
└── extension group
└── extension
TEN runtime 的组成:
| 层级 | 组成 |
|---|---|
| Binding | C++ binding、Go binding、Python binding、JS/TS binding、其他 binding |
| Runtime 能力 | Memory Checker、Reference Management、Thread Management、Extension Management、Graph Management、Connection Management、Metadata Management、Message Management、TenEnv Management 等 |
| 底层实现 | C、Rust |
Extention 之间通过消息进行通信,可以分为 4 种:
- Command:单独的指令。
- Data:文本片段。
- Audio Frame:音频帧。
- Video Frame:视频帧。
每个 Extention 在代码中实现对应消息的处理回调函数,并且可以在回调函数中发送消息给后面的 Extention 节点。
# Python Extention 示例
class MyExtention:
def on_data(self, ten_env: TenEnv, data: Data) -> None:
# 处理文本片段
pass
def on_audio_frame(self, ten_env: TenEnv, audio_frame: AudioFrame) -> None:
# 处理音频
pass
def on_video_frame(self, ten_env: TenEnv, video_frame: VideoFrame) -> None:
# 处理视频
pass
以 TEN Agent 为例,前端摄像头拍摄的场景可以通过 Video Frame 实时传给 Graph 中的 Extention,而例如音频的输出结果可以通过 Audio Frame 返回给前端播放。
消息形式可以概括为:
| 消息模式 | 说明 |
|---|---|
| Single command, Single result | 一条 cmd 对应一个 result |
| Single command, Multiple results | 一条 cmd 对应多个 result |
| Single/Multiple Data-like messages | data、audio frame、video frame 可以连续传递 |
示例
下面举例说明基于 TEN 框架的 TEN Agent 的编排形式。
在 TEN Agent 中,每个 Graph 的起始节点都是 agora_rtc,用于和声网实时交互,包括接收数据和发送数据。
基于多模态实时 API 的 Agent
Extention 编排的 Graph:
flowchart LR
AgoraRTC["agora_rtc<br/>基于声网实时交互"]
Gemini["gemini<br/>多模态模型"]
Weather["weather_tool<br/>天气查询工具"]
AgoraRTC -- "输入 Audio Frame<br/>麦克风" --> Gemini
AgoraRTC -- "输入 Video Frame<br/>摄像头" --> Gemini
Gemini -- "输入 Audio Frame<br/>返回给前端播放" --> AgoraRTC
Gemini -- "如果触发 Function Call<br/>则发送调用工具 Command" --> Weather
这里使用了 Gemini 的实时交互 API,输入音频和图片,输出语音回复。
在开始一次对话时,gemini 会开启一个 Gemini API 的对话 session:
- 每间隔一秒获取当前的 Video Frame,转换为视频传给 Gemini。
- 将 Audio Frame 保存在内存的 Buffer 中,在 Buffer 达到阈值后一次性传给 Gemini。
- 定时拉取 Gemini 的响应,如果是 Function Call 则可以调用工具;如果是语音响应,则通过 Audio Frame 返回。
多个算法集成的 Agent
Extention 编排的 Graph:
flowchart LR
AgoraRTC["agora_rtc<br/>基于声网实时交互"]
ASR["asr<br/>语音转文字"]
Detector["interrupt_detector<br/>判断用户是否在打断 Agent 输出"]
Vision["vision_tool<br/>保存当前视频帧的图片"]
GPT4o["gpt-4o<br/>大语言模型"]
TTS["tts<br/>文字转语音"]
AgoraRTC -- "输入 Audio Frame<br/>用户麦克风音频" --> ASR
ASR -- "输入 Data" --> Detector
Detector -- "输入 Data" --> GPT4o
Detector -- "如果用户打断 Agent 输出<br/>则发送停止响应的 Command" --> GPT4o
AgoraRTC -- "输入 Video Frame<br/>用户摄像头画面" --> Vision
GPT4o -- "如果需要 Function Call<br/>读取当前摄像头画面<br/>则发送调用工具 Command" --> Vision
Vision -- "如果需要 Function Call<br/>读取当前摄像头画面<br/>则发送调用工具 Command" --> GPT4o
GPT4o -- "输入 Data" --> TTS
TTS -- "输入 Audio Frame<br/>返回音频播放" --> AgoraRTC
该 Agent 集成了多个算法:
- 用户输入的音频经过 ASR 转换为文本。
- 文本输入给大模型进行回答,输入响应文本。如果问题和摄像头画面相关,还可以通过 Function Call 读取画面图片,并依赖 GPT-4o 进行识别和回答。
- 大模型的回复经过 TTS 算法转换为音频,输出到前端进行播放。
附录
Graph JSON 配置示例
下面是一个 TEN Agent 中的节点描述和编排的 JSON 文件示例。
{
"name": "va_gemini_v2v",
"auto_start": true,
"nodes": [
{
"type": "extension",
"name": "agora_rtc",
"addon": "agora_rtc",
"extension_group": "rtc",
"property": {
"app_id": "${env:AGORA_APP_ID}",
"token": "",
"channel": "ten_agent_test",
"stream_id": 1234,
"remote_stream_id": 123,
"subscribe_audio": true,
"publish_audio": true,
"publish_data": true,
"subscribe_audio_sample_rate": 24000,
"subscribe_video_pix_fmt": 4,
"subscribe_video": true
}
},
{
"type": "extension",
"name": "v2v",
"addon": "gemini_v2v_python",
"extension_group": "llm",
"property": {
"api_key": "${env:GEMINI_API_KEY}",
"api_version": "v1alpha",
"base_uri": "generativelanguage.googleapis.com",
"dump": true,
"language": "en-US",
"max_tokens": 2048,
"model": "gemini-2.0-flash-exp",
"server_vad": true,
"temperature": 0.9
}
}
]
}