
Asynq Redis 任务队列的实现分析
本文分析了 Redis 任务队列 Asynq 的实现。
任务队列模式
-
Client 可以向指定的队列发送任务。
-
Server 会从队列中一直拉取任务,并会启动多个 Worker 来执行任务(根据设置的并发量,设置最大的 Goroutine 数量)。
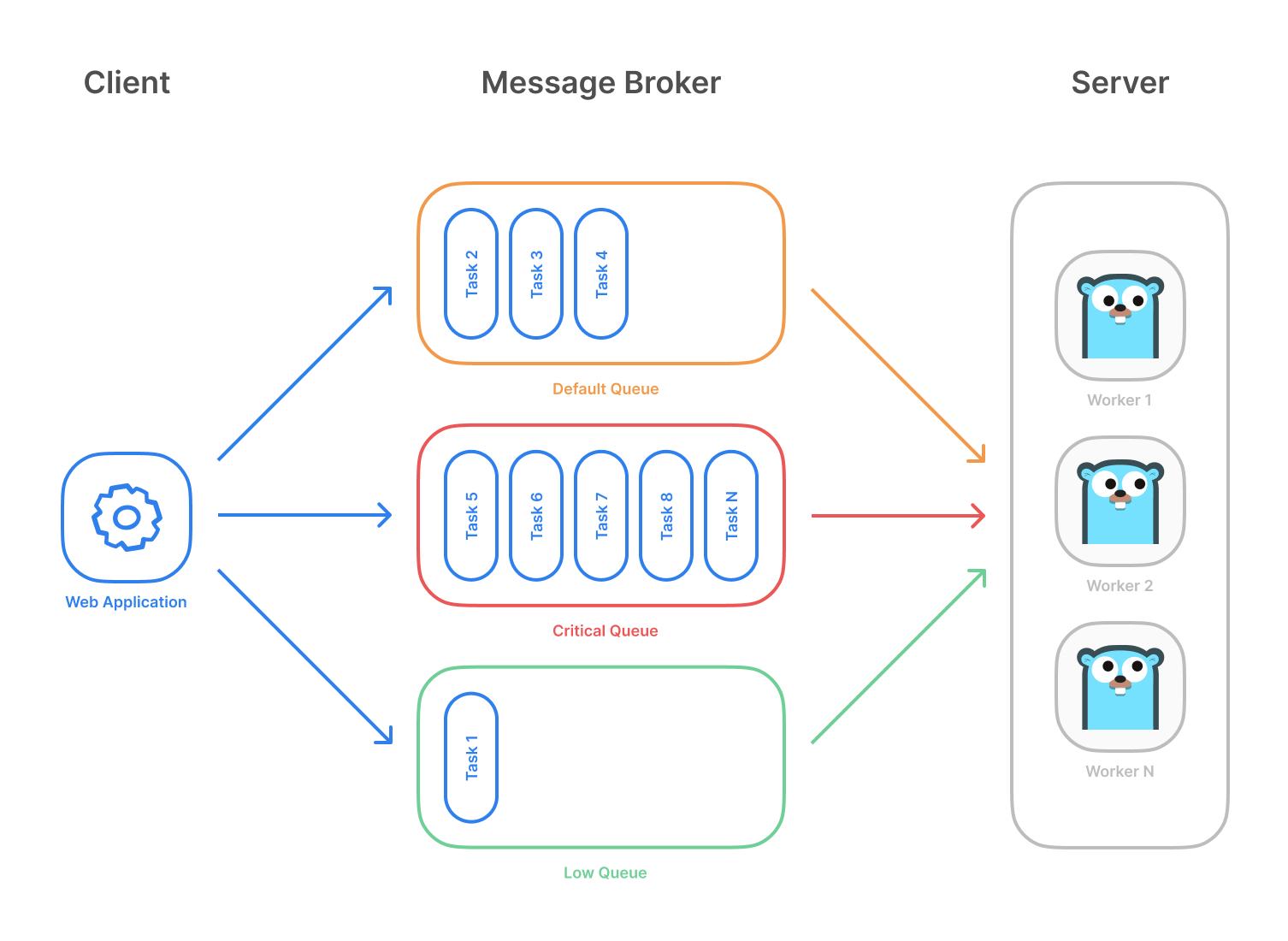
任务状态和生命周期
任务一共有六种状态:
-
Scheduled:入队,但还没有被处理(可以给任务设置延迟处理时间)。- 到了可以被处理的时间,会转换为
Pending。
- 到了可以被处理的时间,会转换为
-
Pending:可以被处理,等待被 Worker 拉取出队。- 被 Worker 拉取出队后,会转换为
Active。
- 被 Worker 拉取出队后,会转换为
-
Active:正在被 Worker 处理。-
如果任务处理成功,但设置了任务保留时间,会转换为
Completed;否则任务被删除。 -
如果任务处理失败,但未到达最大重试次数,会转换为
Retry;否则会转换为Archived。
-
-
Retry:任务失败,但未到达最大重试次数,正在等待重试。 -
Archived:任务失败,但已经到达最大重试次数,作为存档保留。 -
Completed:任务完成,但是按照任务设定的保留时间,会保存一段时间。
+-------------+ +--------------+ +--------------+ +-------------+
| | | | | | Success | |
| Scheduled |----------->| Pending |--------->| Active |---------> | Completed |
| (Optional) | | | | | | (Optional) |
+-------------+ +--------------+ +--------------+ +-------------+
^ | |
| | | Deletion
| | Failed |
| | V
| |
| |
+------+-------+ | +--------------+
| | | | |
| Retry |<--------------+------->| Archived |
| | | |
+--------------+ +--------------+
分组特性:Task Aggregation
任务指定分组后,会被分配到对应的 Group 中,并转换为
Aggregating状态,表示任务在等待批次分配。Group 中的任务会被定期拉取并合并为一个任务批次,最终聚集成一个任务,并进入Pending状态。
Server 组件
-
Forwarder- 从
Scheduled和Retry任务集合中拉取任务,如果是分组的任务,转换为Aggregating;否则,转换为Pending。
- 从
-
Processor-
负责从
Pending队列中拉取任务出队执行。 -
同一时刻只有一个 Goroutine 在调用 Redis 出队,但出队之后的任务可以按照设定的并发数并发执行,也就是多个 Worker 并发运行。
-
-
Aggregator-
负责调度分组的任务。
-
首先检查各个队列中有哪些 Group 可以拉取任务批次,如果可以则从对应 Group 拉取任务批次(批次集合 ID 为 UUID);否则,跳过该 Group。
-
根据用户在 Server 配置的聚集函数,将拉取的任务批次合并为一个任务,然后将合并后的任务入队。
-
删除任务批次信息。
-
-
-
Syncer-
处理异步逻辑,通过 Channel 收集函数调用请求,定期批量执行,将成功的请求去除,并保留失败的请求下次执行。
-
使用场景:
Processor调用 MarkAsComplete / Done / Retry / Archive 失败时,会把请求发给Syncer来循环重试。
-
-
Heartbeater-
Server 定时通过
Heartbeater将 Server 和 Worker 信息通过心跳的方式上报到 Redis 存储中,并且每次上报会延续 Worker 中所有任务的 Lease 时间(持有任务的过期时间)。 -
如果没及时续写,则 Cancel 任务,让任务失败(进而导致
Retry或Archived)。 -
在程序退出时,清理 Server 和 Worker 信息。
-
-
Healthchecker-
Redis 连通性检测能力。可选项,需要配置开启。
-
开启后,定时向 Redis 发送 Ping 指令,并且可以用 Ping 的结果触发自定义的回调函数。
-
-
Janitor- 定期循环各个队列,删除一部分过期的
Completed任务。
- 定期循环各个队列,删除一部分过期的
-
Recoverer-
定期回收 Lease 过期的任务(转换为
Retry或Archive)。 -
定期回收过期没被
Aggregator处理的任务批次,将任务放回分组。
-
Redis 数据存储
asynq:{<qname>}:t:<task_id>
-
类型:
Hash -
作用:存储每个任务的信息。
-
子 Key:
-
msg:序列化后的任务 Payload -
state:任务状态 -
pending_since:Pending 时的时间戳 -
group:任务分组名称(只有使用任务聚集模式才会有)。
-
asynq:{<qname>}:g:<gname>
-
类型:
Sorted Set -
作用:某个 Group 中所有任务的集合(只有使用任务聚集模式才会用到)。
-
实现:元素为任务 ID,score 为任务被聚集到 Group 时的时间戳。
asynq:{<qname>}:groups
-
类型:
Set -
作用:队列中所有 Group 的集合(只有使用任务聚集模式才会用到)。
-
实现:元素为 Group 名称。
asynq:{<qname>}:aggregation_sets
-
类型:
Sorted Set -
作用:队列中的任务批次 ID 集合。
-
实现:元素为 Key
asynq:{<qname>}:g:<gname>:<aggregation_set_id>,score 为任务批次的过期时间(Key 根据时间从小到大排序)。
asynq:{<qname>}:g:<gname>:<aggregation_set_id>
-
类型:
Sorted Set -
作用:任务批次中的任务 ID 集合。
-
实现:元素为任务 ID,score 为任务加入 Group 的时间(任务根据时间从小到大排序)。
asynq:{<qname>}:pending
-
类型:
List -
作用:Pending 任务队列。
-
实现:列表元素为任务 ID。
asynq:{<qname>}:scheduled
-
类型:
Sorted Set -
作用:Scheduled 任务集合。
-
实现:元素为任务 ID,score 为任务可以被拉入 Pending 队列的时间(任务根据时间从小到大排序)。
asynq:{<qname>}:active
-
类型:
List -
作用:存储正在处理的任务,以队列的形式。
-
实现:列表元素为任务 ID。
asynq:{<qname>}:lease
-
类型:
Sorted Set -
作用:任务 Lease 过期时间记录。
-
实现:元素为任务 ID,score 为任务的 Lease 过期时间(任务根据时间从小到大排序)。
asynq:{<qname>}:retry
-
类型:
Sorted Set -
作用:Retry 任务集合。
-
实现:元素为任务 ID,score 为任务信息可以重试的时间(任务根据时间从小到大排序)。
asynq:{<qname>}:completed
-
类型:
Sorted Set -
作用:Completed 任务集合。
-
实现:元素为任务 ID,score 为任务信息可以被删除的时间(任务根据时间从小到大排序)。
asynq:{<qname>}:paused
-
类型:
String -
作用:存储被暂停的队列(被暂停的队列中的任务不可以被出队处理)。
-
实现:Value 为队列被暂停的时间。
asynq:servers:{<host:pid:sid>}
-
类型:
String -
作用:存储 Server 信息。
-
实现:Value 为 Server 信息。
asynq:workers:{<host:pid:sid>}
-
类型:
Hash -
作用:存储 Server 中每个 Woker 的信息。
-
实现:子 Key 为 Worker ID,子 Value 为 Worker 信息。
队列操作(Redis 脚本)
任务入队 [Enqueue]
场景:Client 向队列发送任务。
实现:将任务加入 Pending 队列,并存储任务信息和状态(设置任务状态为 Pending)。
时间复杂度:O(1)
# Input:
# KEYS[1] -> asynq:{<qname>}:t:<task_id>
# KEYS[2] -> asynq:{<qname>}:pending
# -------
# ARGV[1] -> task message data
# ARGV[2] -> task ID
# ARGV[3] -> current unix time in nsec
#
# Output:
# Returns 1 if successfully enqueued
# Returns 0 if task ID already exists
# 检查是否已经设置过任务信息
if redis.call("EXISTS", KEYS[1]) == 1 then
return 0
end
# 写入任务信息
redis.call("HSET", KEYS[1],
"msg", ARGV[1],
"state", "pending",
"pending_since", ARGV[3])
# 放入 Pending 队列
redis.call("LPUSH", KEYS[2], ARGV[2])
return 1
延迟调度 [Schedule]
场景:Client 延迟调度任务,希望任务在一定的时间之后再被执行。
实现:将任务加入 Scheduled 集合,并存储任务信息和状态(设置任务状态为 Scheduled)。
时间复杂度:O(log(N)),其中 N 为 Scheduled 集合的元素数量
# KEYS[1] -> asynq:{<qname>}:t:<task_id>
# KEYS[2] -> asynq:{<qname>}:scheduled
# -------
# ARGV[1] -> task message data
# ARGV[2] -> process_at time in Unix time
# ARGV[3] -> task ID
#
# Output:
# Returns 1 if successfully enqueued
# Returns 0 if task ID already exists
# 检查是否已经设置过任务信息
if redis.call("EXISTS", KEYS[1]) == 1 then
return 0
end
# 写入任务信息
redis.call("HSET", KEYS[1],
"msg", ARGV[1],
"state", "scheduled")
# 加入 Scheduled 集合
redis.call("ZADD", KEYS[2], ARGV[2], ARGV[3])
return 1
任务出队 [Dequeue]
场景:
Server的Processor组件从队列中拉取任务,给 Worker 执行。实现:从 Pending 队列拉取一个任务,并放到 Active 队列中。如果能拉取到,设置任务的状态为 Active。然后,将任务加入 Lease 集合。最后返回任务 Payload。
时间复杂度:O(log(N)),其中 N 为 Lease 集合的元素数量
# Input:
# KEYS[1] -> asynq:{<qname>}:pending
# KEYS[2] -> asynq:{<qname>}:paused
# KEYS[3] -> asynq:{<qname>}:active
# KEYS[4] -> asynq:{<qname>}:lease
# -------
# ARGV[1] -> initial lease expiration Unix time
# ARGV[2] -> task key prefix (asynq:{qname}t:)
#
# Output:
# Returns nil if no processable task is found in the given queue.
# Returns an encoded TaskMessage.
#
# Note: dequeueCmd checks whether a queue is paused first, before
# calling RPOPLPUSH to pop a task from the queue.
# 检查队列是否已暂停,只有未暂停才执行逻辑
if redis.call("EXISTS", KEYS[2]) == 0 then
# 将一个任务从 Pending 队列转移到 Active 队列
local id = redis.call("RPOPLPUSH", KEYS[1], KEYS[3])
if id then
# asynq:{qname}t:{task_id},也就是任务信息 Key
local key = ARGV[2] .. id
redis.call("HSET", key, "state", "active")
redis.call("HDEL", key, "pending_since")
# 将任务 ID 加入 Lease 集合
redis.call("ZADD", KEYS[4], ARGV[1], id)
return redis.call("HGET", key, "msg")
end
end
return nil
任务结束 [Done]
场景:Worker 执行任务成功,立即删除任务。
实现:从 Active 队列和 Lease 集合中删除任务,并删除任务的信息。
时间复杂度:O(N + log(M)),其中 N 为 Active 队列的元素数量,M 为 Lease 集合的元素数量
# KEYS[1] -> asynq:{<qname>}:active
# KEYS[2] -> asynq:{<qname>}:lease
# KEYS[3] -> asynq:{<qname>}:t:<task_id>
# -------
# ARGV[1] -> task ID
# 在 Active 队列中删除任务 ID,如果队列里没有,则直接返回
# https://redis.io/docs/latest/commands/lrem/
# 时间复杂度:O(N),N 为 Active 队列的元素数量
if redis.call("LREM", KEYS[1], 0, ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Lease 集合中删除任务 ID,如果集合里没有,则直接返回
# https://redis.io/docs/latest/commands/zrem/
# 时间复杂度:O(log(N)),N 为 Lease 集合的元素数量
if redis.call("ZREM", KEYS[2], ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 删除任务信息,如果没有则直接返回
if redis.call("DEL", KEYS[3]) == 0 then
return redis.error_reply("NOT FOUND")
end
return redis.status_reply("OK")
标记任务完成(信息延迟删除) [MarkAsComplete]
场景:Worker 执行任务成功,需要等待指定的时间后再删除任务信息。
实现:将任务从 Active 队列和 Lease 集合中删除,加入 Completed 集合,并设置状态为 Completed。
时间复杂度:O(N + log(M) + log(K)),其中 N 为 Active 队列的元素数量,M 为 Lease 集合的元素数量,K 为 Completed 集合的元素数量
# KEYS[1] -> asynq:{<qname>}:active
# KEYS[2] -> asynq:{<qname>}:lease
# KEYS[3] -> asynq:{<qname>}:completed
# KEYS[4] -> asynq:{<qname>}:t:<task_id>
# -------
# ARGV[1] -> task ID
# ARGV[2] -> task expiration time in unix time
# ARGV[3] -> task message data
# 在 Active 队列中删除任务 ID,如果队列里没有,则直接返回
if redis.call("LREM", KEYS[1], 0, ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Lease 集合中删除任务 ID,如果集合里没有,则直接返回
if redis.call("ZREM", KEYS[2], ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Completed 集合中添加任务 ID
# 时间复杂度:O(log(N)),N 为 Completed 集合的元素数量
if redis.call("ZADD", KEYS[3], ARGV[2], ARGV[1]) ~= 1 then
return redis.error_reply("INTERNAL")
end
# 存储任务 Payload,并设置任务的状态为 Completed
redis.call("HSET", KEYS[4], "msg", ARGV[3], "state", "completed")
return redis.status_reply("OK")
重试任务 [Retry]
场景:任务执行失败,但没有超过最大重试次数(任务重试次数记录在 Payload 中,每次重试加一)。
实现:和 MarkAsComplete 操作类似。将任务从 Action 队列和 Lease 集合中删除,加入 Retry 集合,存储任务信息并更新任务状态为 Retry。
时间复杂度:O(N + log(M) + log(K)),其中 N 为 Active 队列的元素数量,M 为 Lease 集合的元素数量,K 为 Retry 集合的元素数量
# KEYS[1] -> asynq:{<qname>}:t:<task_id>
# KEYS[2] -> asynq:{<qname>}:active
# KEYS[3] -> asynq:{<qname>}:lease
# KEYS[4] -> asynq:{<qname>}:retry
# -------
# ARGV[1] -> task ID
# ARGV[2] -> updated base.TaskMessage value
# ARGV[3] -> retry_at UNIX timestamp
# 从 Active 队列中删除任务 ID,如果队列里没有,则直接返回
if redis.call("LREM", KEYS[2], 0, ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 从 Lease 集合中删除任务 ID,如果集合里没有,则直接返回
if redis.call("ZREM", KEYS[3], ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 将任务 ID 加入 Retry 集合,score 为可以开始重试的时间
redis.call("ZADD", KEYS[4], ARGV[3], ARGV[1])
# 存储任务 Payload,并设置任务的状态为 Retry
redis.call("HSET", KEYS[1], "msg", ARGV[2], "state", "retry")
return redis.status_reply("OK")
失败任务存档 [Archive]
场景:任务执行失败,并且到达最大重试次数,或者返回了无需重试的错误(SkipRetry),将任务存档。
实现:和 MarkAsComplete 操作类似。将任务从 Action 队列和 Lease 集合中删除,加入 Archived 集合,存储任务信息并更新任务状态为 Archived。此过程还会根据指定的最长保留时间(比如90天)和最大数量(比如100个)清理 Archived 集合。
时间复杂度:O(N + log(M) + log(K) + L),其中 N 为 Active 队列的元素数量,M 为 Lease 集合的元素数量,K 为 Archived 集合的元素数量,L 为 Archived 集合中被清理的元素数量
# KEYS[1] -> asynq:{<qname>}:t:<task_id>
# KEYS[2] -> asynq:{<qname>}:active
# KEYS[3] -> asynq:{<qname>}:lease
# KEYS[4] -> asynq:{<qname>}:archived
# -------
# ARGV[1] -> task ID
# ARGV[2] -> updated base.TaskMessage value
# ARGV[3] -> died_at UNIX timestamp
# ARGV[4] -> cutoff timestamp (e.g., 90 days ago)
# ARGV[5] -> max number of tasks in archive (e.g., 100)
# 在 Active 队列中删除任务 ID,如果队列里没有,则直接返回
if redis.call("LREM", KEYS[2], 0, ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Lease 集合中删除任务 ID,如果集合里没有,则直接返回
if redis.call("ZREM", KEYS[3], ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Archived 集合中添加任务 ID
redis.call("ZADD", KEYS[4], ARGV[3], ARGV[1])
# 【根据时间处理 Archived 集合】
# 在 Archived 集合中,删除指定时间之前的所有任务 ID
# https://redis.io/docs/latest/commands/zremrangebyscore/
redis.call("ZREMRANGEBYSCORE", KEYS[4], "-inf", ARGV[4])
# 【根据集合数量处理 Archived 集合】
# 在 Archived 集合中,删除一定数量的旧任务,保证集合中的数量不超过指定的最大数量
# https://redis.io/docs/latest/commands/zremrangebyrank/
redis.call("ZREMRANGEBYRANK", KEYS[4], 0, -ARGV[5])
# 设置任务的状态为 Archived。
redis.call("HSET", KEYS[1], "msg", ARGV[2], "state", "archived")
return redis.status_reply("OK")`)
重入队列 [Requeue]
场景:
Server的Processor组件退出时(也就是Server退出),会发送 abort 信号,此时如果任务没处理完,则重新放入Pending队列(之后优先执行),并且更新任务状态为Pending。实现:将任务从 Action 队列和 Lease 集合中删除,加入 Pending 队列,并更新任务状态为 Pending。
时间复杂度:O(N + log(M)),其中 N 为 Active 队列的元素数量,M 为 Lease 集合的元素数量
# KEYS[1] -> asynq:{<qname>}:active
# KEYS[2] -> asynq:{<qname>}:lease
# KEYS[3] -> asynq:{<qname>}:pending
# KEYS[4] -> asynq:{<qname>}:t:<task_id>
# -------
# ARGV[1] -> task ID
# Note: Use RPUSH to push to the head of the queue.
# 在 Active 队列中删除任务 ID,如果队列里没有,则直接返回
if redis.call("LREM", KEYS[1], 0, ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Lease 集合中删除任务 ID,如果集合里没有,则直接返回
if redis.call("ZREM", KEYS[2], ARGV[1]) == 0 then
return redis.error_reply("NOT FOUND")
end
# 在 Pending 队列添加任务 ID(之后会被首先拉取执行)
redis.call("RPUSH", KEYS[3], ARGV[1])
# 设置任务状态为 Pending
redis.call("HSET", KEYS[4], "state", "pending")
return redis.status_reply("OK")`)
暂停队列 [PauseQueue]
场景:用户通过命令行工具的指令
pause <queue> [<queue>...]暂停指定的队列,被暂停的队列可以让任务入队,但是不能让任务出队。如果队列已经暂停,会报错。实现:根据队列名称设置 Key,且写入的值为当前的时间戳。如果 Key 已经存在,不会更新。
时间复杂度:O(1)
SETNX asynq:{<qname>}:paused <current-unix-time>
恢复暂停的队列 [UnpauseQueue]
场景:用户通过命令行工具的指令
resume <queue> [<queue>...]暂停指定的队列实现:根据队列名称删除 Key。
时间复杂度:O(1)
DEL asynq:{<qname>}:paused
将任务加入分组 [AddToGroup]
场景:任务入队时指定分组名(Group)会触发该逻辑,支持任务聚合到特定的分组,用于批量执行。根据任务指定的 Group,一段时间内入队并指定这个 Group 的任务会被聚合起来,等时间到之后会一并被出队执行。
实现:存储任务信息和状态(设置任务状态为 Aggregating),将任务添加到对应 Group 的任务集合中,并将 Group 加入 Group 集合。
时间复杂度:O(log(N)),其中 N 为 Group 任务集合中的元素数量
# KEYS[1] -> asynq:{<qname>}:t:<task_id>
# KEYS[2] -> asynq:{<qname>}:g:<gname>
# KEYS[3] -> asynq:{<qname>}:groups
# -------
# ARGV[1] -> task message data
# ARGV[2] -> task ID
# ARGV[3] -> current time in Unix time
# ARGV[4] -> group key
#
# Output:
# Returns 1 if successfully added
# Returns 0 if task ID already exists
# 检查是否已经设置过任务信息
if redis.call("EXISTS", KEYS[1]) == 1 then
return 0
end
# 写入任务信息,设置任务的状态为 Aggregating
redis.call("HSET", KEYS[1],
"msg", ARGV[1],
"state", "aggregating",
"group", ARGV[4])
# 将任务 ID 加入指定 Group 任务集合
# 时间复杂度为 O(log(N)),其中 N 为 Group 任务集合中的元素数量
redis.call("ZADD", KEYS[2], ARGV[3], ARGV[2])
# 将 Group 名称加入 Group 集合。
# 时间复杂度为 O(1)
redis.call("SADD", KEYS[3], ARGV[4])
return 1
任务分组聚集状态检查 [AggregationCheck]
场景:
Server的Aggregator组件会定时检查所有队列中的 Group。首先创建一个 UUID 作为任务批次 ID,当 Group 中的任务满足一定的条件(数量或时间),从 Group 中拉取一批任务作为一个批次(批次 ID 为指定的 UUID),用于合并执行;否则,不处理该 Group。实现:检查指定 Group 集合中的任务状态,如果满足批次条件,则拉取任务加入批次任务集合;否则,不处理 Group 中的任务。
时间复杂度:O(log(N) + log(M) + K),其中 N 为 Group 任务集合中的元素数量,M 为队列中的 Group 数量,K 为一个 Group 的最大限制数量。
# aggregationCheckCmd checks the given group for whether to create an aggregation set.
# An aggregation set is created if one of the aggregation criteria is met:
# 1) group has reached or exceeded its max size
# 2) group's oldest task has reached or exceeded its max delay
# 3) group's latest task has reached or exceeded its grace period
# if aggreation criteria is met, the command moves those tasks from the group
# and put them in an aggregation set. Additionally, if the creation of aggregation set
# empties the group, it will clear the group name from the all groups set.
#
# KEYS[1] -> asynq:{<qname>}:g:<gname>
# KEYS[2] -> asynq:{<qname>}:g:<gname>:<aggregation_set_id>
# KEYS[3] -> asynq:{<qname>}:aggregation_sets
# KEYS[4] -> asynq:{<qname>}:groups
# -------
# ARGV[1] -> max group size
# ARGV[2] -> max group delay in unix time
# ARGV[3] -> start time of the grace period
# ARGV[4] -> aggregation set expire time
# ARGV[5] -> current time in unix time
# ARGV[6] -> group name
#
# Output:
# Returns 0 if no aggregation set was created
# Returns 1 if an aggregation set was created
#
# Time Complexity:
# O(log(N) + M) with N being the number tasks in the group zset
# and M being the max size.
# 查看 Group 中有多少个任务
local size = redis.call("ZCARD", KEYS[1])
if size == 0 then
return 0
end
# 一个 Group 中的最大任务数量
local maxSize = tonumber(ARGV[1])
#【情况一:检查任务数是否超过设定的最大数量,如果是,则拉取 maxSize 个任务作为一个批次】
if maxSize ~= 0 and size >= maxSize then
# 筛选出放入分组时间最早的 maxSize 个任务
local res = redis.call("ZRANGE", KEYS[1], 0, maxSize-1, "WITHSCORES")
for i=1, table.getn(res)-1, 2 do
# 将取出的任务放到当前的指定的任务批次中
redis.call("ZADD", KEYS[2], tonumber(res[i+1]), res[i])
end
# 将拉取的任务从 Group 任务集合中删除
redis.call("ZREMRANGEBYRANK", KEYS[1], 0, maxSize-1)
# 将 asynq:{<qname>}:g:<gname>:<aggregation_set_id> 放入任务批次集合,score 为过期时间
redis.call("ZADD", KEYS[3], ARGV[4], KEYS[2])
# 如果这个 Group 的任务都被取出,直接将 Group ID 丛 Group 集合中删除
if size == maxSize then
# 时间复杂度 O(1)
redis.call("SREM", KEYS[4], ARGV[6])
end
return 1
end
#【情况二:检查最早的任务是否已等待足够时间,如果是,则拉取 maxSize 个任务作为一个批次】
local maxDelay = tonumber(ARGV[2])
local currentTime = tonumber(ARGV[5])
if maxDelay ~= 0 then
# 查找最早放入 Group 中的任务
local oldestEntry = redis.call("ZRANGE", KEYS[1], 0, 0, "WITHSCORES")
# 获取该任务的放入时间
local oldestEntryScore = tonumber(oldestEntry[2])
# 计算需要被删除的放入时间 DDL
local maxDelayTime = currentTime - maxDelay
# 如果最早的任务已经等待到指定的时间,拉取 maxSize 个任务作为一个批次(同上)
if oldestEntryScore <= maxDelayTime then
# 筛选出放入分组时间最早的 maxSize 个任务
local res = redis.call("ZRANGE", KEYS[1], 0, maxSize-1, "WITHSCORES")
for i=1, table.getn(res)-1, 2 do
# 将取出的任务放到当前的指定的任务批次中
redis.call("ZADD", KEYS[2], tonumber(res[i+1]), res[i])
end
# 将拉取的任务从 Group 任务集合中删除
redis.call("ZREMRANGEBYRANK", KEYS[1], 0, maxSize-1)
# 将 asynq:{<qname>}:g:<gname>:<aggregation_set_id> 放入任务批次集合,score 为过期时间
redis.call("ZADD", KEYS[3], ARGV[4], KEYS[2])
# 如果 Group 中的任务数量小于 maxSize(任务全部被拉取),删除这个 Group 信息
if size <= maxSize or maxSize == 0 then
redis.call("SREM", KEYS[4], ARGV[6])
end
return 1
end
end
#【情况三:检查最新的任务是否已等待足够时间,如果是,则拉取 maxSize 个任务作为一个批次】
# 查找最近一个放入 Group 中的任务
local latestEntry = redis.call("ZREVRANGE", KEYS[1], 0, 0, "WITHSCORES")
local latestEntryScore = tonumber(latestEntry[2])
local gracePeriodStartTime = currentTime - tonumber(ARGV[3])
# 如果最近的一个的任务已经等待到指定的时间,拉取 maxSize 个任务作为一个批次(同上)
if latestEntryScore <= gracePeriodStartTime then
# 筛选出放入分组时间最早的 maxSize 个任务
local res = redis.call("ZRANGE", KEYS[1], 0, maxSize-1, "WITHSCORES")
for i=1, table.getn(res)-1, 2 do
# 将取出的任务放到当前的指定的任务批次中
redis.call("ZADD", KEYS[2], tonumber(res[i+1]), res[i])
end
# 将拉取的任务从 Group 任务集合中删除
redis.call("ZREMRANGEBYRANK", KEYS[1], 0, maxSize-1)
# 将 asynq:{<qname>}:g:<gname>:<aggregation_set_id> 放入任务批次集合,score 为过期时间
redis.call("ZADD", KEYS[3], ARGV[4], KEYS[2])
# 如果 Group 中的任务数量小于 maxSize(任务全部被拉取),删除这个 Group 信息
if size <= maxSize or maxSize == 0 then
redis.call("SREM", KEYS[4], ARGV[6])
end
return 1
end
return 0
读取一个批次中任务信息 [ReadAggregationSet]
场景:在需要执行任务批次时(也就是在
AggregationCheck时创建了批次),Server的Aggregator组件会加载指定批次的任务(之后用于合并执行)。实现:读取任务批次中所有的任务,读取所有 Payload。
时间复杂度:O(N),其中 N 为指定批次任务集合中的元素数量。
# KEYS[1] -> asynq:{<qname>}:g:<gname>:<aggregation_set_id>
# ------
# ARGV[1] -> task key prefix
#
# Output:
# Array of encoded task messages
#
# Time Complexity:
# O(N) with N being the number of tasks in the aggregation set.
local msgs = {}
# 获取指定任务批次中的所有任务 ID
local ids = redis.call("ZRANGE", KEYS[1], 0, -1)
for _, id in ipairs(ids) do
# asynq:{<qname>}:t:<task_id> 任务信息
local key = ARGV[1] .. id
table.insert(msgs, redis.call("HGET", key, "msg"))
end
return msgs
删除一个任务批次的信息 [DeleteAggregationSet]
场景:
Server的Aggregator组件将指定批次的聚合任务放入任务队列后,删除任务批次的相关信息。实现:读取任务批次中所有的任务,并删除所有任务信息和指定的批次信息。
时间复杂度:O(N + log(M)),其中 N 为指定批次任务集合中的元素数量,M 为任务批次集合中的元素数量。
# KEYS[1] -> asynq:{<qname>}:g:<gname>:<aggregation_set_id>
# KEYS[2] -> asynq:{<qname>}:aggregation_sets
# -------
# ARGV[1] -> task key prefix
#
# Output:
# Redis status reply
#
# Time Complexity:
# max(O(N), O(log(M))) with N being the number of tasks in the aggregation set
# and M being the number of elements in the all-aggregation-sets list.
# 读取任务批次中的所有任务 ID
local ids = redis.call("ZRANGE", KEYS[1], 0, -1)
for _, id in ipairs(ids) do
# 删除所有任务 ID 对应的任务信息
redis.call("DEL", ARGV[1] .. id)
end
# 删除任务批次信息
redis.call("DEL", KEYS[1])
# 在任务批次集合中删除当前任务批次
redis.call("ZREM", KEYS[2], KEYS[1])
return redis.status_reply("OK")
回收过期的任务批次 [ReclaimStaleAggregationSets]
场景:
Server的Recoverer组件清理到期的任务批次(比如在AggregationCheck后因程序崩溃而没有合并执行和删除任务批次),把任务放回原来的分组。实现:获取该批次的所有任务,并放回原来的 Group,然后删除过期的批次信息。
# KEYS[1] -> asynq:{<qname>}:aggregation_sets
# -------
# ARGV[1] -> current time in unix time
# 查找所有过期的批次,获得过期的 asynq:{<qname>}:g:<gname>:<aggregation_set_id> 列表
# (由于 score 是过期时间,所以当前时间之前的批次都过期了)
local staleSetKeys = redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", ARGV[1])
for _, key in ipairs(staleSetKeys) do
# 解析 asynq:{<qname>}:g:<gname>:<aggregation_set_id>,得到的 groupKey 为 asynq:{<qname>}:g:<gname>
local idx = string.find(key, ":[^:]*$")
local groupKey = string.sub(key, 1, idx-1)
# 获取 asynq:{<qname>}:g:<gname>:<aggregation_set_id> 中所有的任务 ID
local res = redis.call("ZRANGE", key, 0, -1, "WITHSCORES")
for i=1, table.getn(res)-1, 2 do
# 将获取到的任务 ID 放回原来的 Group
redis.call("ZADD", groupKey, tonumber(res[i+1]), res[i])
end
# 删除指定批次
redis.call("DEL", key)
end
# 删除所有过期的批次
redis.call("ZREMRANGEBYSCORE", KEYS[1], "-inf", ARGV[1])
return redis.status_reply("OK")
清理过期的已完成任务 [DeleteExpiredCompletedTasks]
场景:
Server的Janitor组件定期遍历各个队列,清理过期的已完成任务(被 MarkAsComplete 的任务)。实现:从 Completed 集合中删除过期时间在当前时间之前的任务,并且删除任务对应的存储信息。
时间复杂度:O(M * log(N)),其中 N 为 Completed 集合的元素数量,M 为被删除的任务数量。
# KEYS[1] -> asynq:{<qname>}:completed
# -------
# ARGV[1] -> current time in unix time
# ARGV[2] -> task key prefix
# ARGV[3] -> batch size (i.e. maximum number of tasks to delete)
# -------
# Returns the number of tasks deleted.
# 从 Completed 集合获取当前时间戳之前的所有元素,并且返回的最大数量。
local ids = redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", ARGV[1], "LIMIT", 0, tonumber(ARGV[3]))
# 处理返回的所有待删除元素。
for _, id in ipairs(ids) do
# 删除 asynq:{<qname>}:t:<task_id>
redis.call("DEL", ARGV[2] .. id)
# 从 Completed 集合中删除任务 ID
# 时间复杂度为 O(N),N 为 Completed 集合的元素数量
redis.call("ZREM", KEYS[1], id)
end
# 返回 ids 的长度。
return table.getn(ids)
Scheduled 或 Retry 到期任务清理 [Forward]
场景:
Server的Forwarder组件将Scheduled或Retry集合中达到设定时间的任务进行清理,切换为Aggregating或Pending状态。实现:查找 Scheduled 集合或 Retry 集合中到期的任务,如果已经在 Group 中,则切换为 Aggregating 状态(等待重新合并执行);否则切换为 Pending 状态(等待重新执行)。
时间复杂度:O(M * log(NK)),其中其中 N 为 Scheduled 集合或 Retry 集合中的元素数量,M 为返回的元素数量,K 为 Group 任务集合中的元素数量
# KEYS[1] -> source queue (e.g. asynq:{<qname>}:scheduled or asynq:{<qname>}:retry})
# KEYS[2] -> asynq:{<qname>}:pending
# -------
# ARGV[1] -> current unix time in seconds
# ARGV[2] -> task key prefix
# ARGV[3] -> current unix time in nsec
# ARGV[4] -> group key prefix
# Note: Script moves tasks up to 100 at a time to keep the runtime of script short.
# 从 Scheduled 集合或 Retry 集合中查找到期时间在当前时间之前的任务
# 时间复杂度为 O(log(N) + M),其中 N 为 Scheduled 集合或 Retry 集合中的元素数量,M 为返回的元素数量
local ids = redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", ARGV[1], "LIMIT", 0, 100)
for _, id in ipairs(ids) do
# 任务信息 asynq:{<qname>}:t:<task_id>
local taskKey = ARGV[2] .. id
# 检查任务是否在 Group 中
local group = redis.call("HGET", taskKey, "group")
if group and group ~= '' then
# 【如果任务在 Group 中】
# 将任务 ID 加入 Group 任务集合中(Key 为 asynq:{<qname>}:g:<gname>)
# 时间复杂度为 O(log(N)),其中 N 为 Group 任务集合中的元素数量
redis.call("ZADD", ARGV[4] .. group, ARGV[1], id)
# 从 Scheduled 集合或 Retry 集合删除任务 ID
# 时间复杂度为 O(log(N)),其中 N 为 Scheduled 集合或 Retry 集合中的元素数量
redis.call("ZREM", KEYS[1], id)
# 设置任务状态为 Aggregating
redis.call("HSET", taskKey,
"state", "aggregating")
else
# 【如果任务不在 Group 中】
# 将任务 ID 加入 Pending 队列
redis.call("LPUSH", KEYS[2], id)
# 从 Scheduled 集合或 Retry 集合删除任务 ID
# 时间复杂度为 O(log(N)),其中 N 为 Scheduled 集合或 Retry 集合中的元素数量
redis.call("ZREM", KEYS[1], id)
# 将任务状态设置为 Pending
redis.call("HSET", taskKey,
"state", "pending",
"pending_since", ARGV[3])
end
end
# 返回 ids 的长度。
return table.getn(ids)
续写 Lease [ExtendLease]
场景:
Server的Heartbeater组件续写 Lease。实现:更新队列 Lease 的任务过期时间。
# XX 表示仅当任务 ID 存在时,才更新 score(过期时间)
ZADD XX asynq:{<qname>}:lease <expire_at> <task_id> <expire_at> <task_id> <expire_at> <task_id>
Server 和 Worker 信息上报 [WriteServerState]
场景:
Server的Heartbeater组件定时上报 Server 和 Worker 状态信息。
# KEYS[1] -> asynq:servers:{<host:pid:sid>}
# KEYS[2] -> asynq:workers:{<host:pid:sid>}
# -------
# ARGV[1] -> TTL in seconds
# ARGV[2] -> server info
# ARGV[3:] -> alternate key-value pair of (worker id, worker data)
# Note: Add key to ZSET with expiration time as score.
# ref: https://github.com/antirez/redis/issues/135#issuecomment-2361996
redis.call("SETEX", KEYS[1], ARGV[1], ARGV[2])
redis.call("DEL", KEYS[2])
for i = 3, table.getn(ARGV)-1, 2 do
redis.call("HSET", KEYS[2], ARGV[i], ARGV[i+1])
end
redis.call("EXPIRE", KEYS[2], ARGV[1])
return redis.status_reply("OK")
清理 Server 和 Worker 信息 [ClearServerState]
场景:
Server的Heartbeater组件退出时,清理 Server 和 Worker 状态信息。
# KEYS[1] -> asynq:servers:{<host:pid:sid>}
# KEYS[2] -> asynq:workers:{<host:pid:sid>}
redis.call("DEL", KEYS[1])
redis.call("DEL", KEYS[2])
return redis.status_reply("OK")
Redis 集群支持
Asynq 支持 Redis 集群,在 Redis 脚本中操作的 Key 都在同一个分片上。这是因为使用了 Redis 的 Hash Tag 特性,可关注 Key 中的 {}。